
The Shazam for People discussion revisited as an article, ‘Identity Voyeurism‘, in September 2015’s British Computer Society (BCS) IT Now Magazine, made all the more relevant by recent breaches of personal privacy …

There’s more than one type of identity ‘crisis’. Conventional identity ‘theft’ is one thing but what of identity ‘voyeurism’? How much of ‘us’ is ‘in the shop window’ anyway? Are we in control? What are the risks? And where’s it heading?
The next time you’re on public transport, try playing the ‘Prof on a Train’ (PoaT) game. (It doesn’t really have to be a train or an academic but it’s a good example to work with.) Take a look at the person opposite you. Armed only with your senses, intelligence, intuition and an Internet connection, how much can you find out about them?
Well, if they’re quietly dozing in the corner, unremarkably dressed, with no distinguishing features whatsoever, you’ll probably lose. However, any activity at all or any visible clues might give you a chance. Are they doing, reading, saying or wearing anything? Who’s with them? Are they easier to identify? Where did they get on and do you know where they’re going? Anything odd? Here’s the basic strategy, on which PoaT is based:
They’re reading an academic paper on a certain subject (X) and you know where they got on (Y). A quick look at the photos on the ‘Department of X’ webpage for the ‘University of Y’ might be enough.
Academics aren’t the only people who proclaim their achievements so publicly, of course. Something as simple as a business card in clear sight gives an even easier win. Once, you’ve named them, Google takes care of the rest. Most information is free but a small amount (county court judgements, for example) might be behind a paywall. Data-mining is easy; unique identification is the challenge. (Unusual names help a little.)
It won’t always be that straightforward, of course: not everyone has a dedicated webpage … yet, and, even then, it won’t always succeed. This is where you and the Internet have to work together. A cleverly-constructed search based on several key-words might just do the trick. Each extra feature narrows the search. You couldn’t process a query so complex but a search engine can. This gives the general idea.
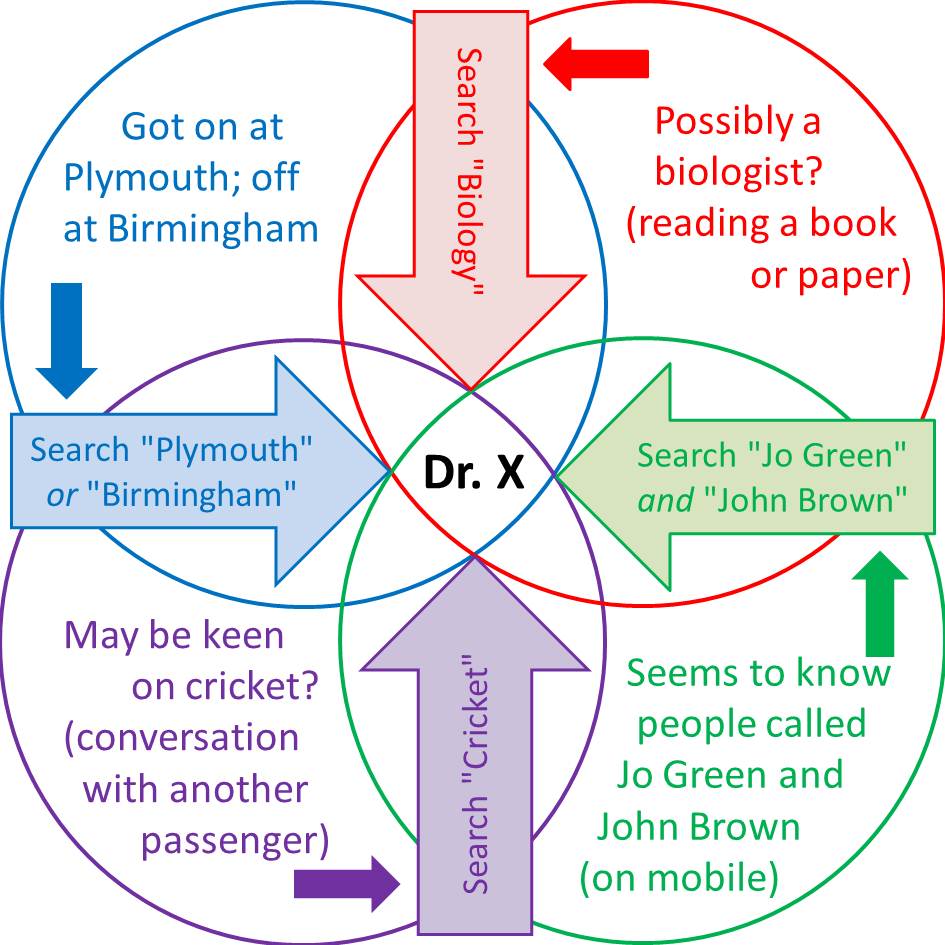
Now, there are two fairly obvious things about PoaT:
- It’s of dubious ethicality (yes, we were going to say that eventually), and
- It’s going to get easier to play as time goes by – as more individual information gets put online and search algorithms become more sophisticated.
So how might PoaT be ‘played’ in a few years’ time? More precisely, how could we make sure we ‘win’?
Well, as with most such processes, the idea would be to automate it as far as possible. For the determined ‘identity voyeur’, this would mean:
- Automatic recognition and identification through hardware [enhancing our senses],
- Improved searching through semantic software [enhancing our intelligence], and
- Integrating (a) and (b) to work, not as discrete concepts but, as one – through iteration/feedback [enhancing our intuition].
Possible tools for automatic recognition (a) include: face-recognition; voice-analysis; fingerprints; gait-analysis; body size/shape-analysis; age-estimation; breath-analysis; DNA; biometrics; odour; clothes/uniform/badges; the car/bike they drive/ride; any identifiable technology on/in their person; location/occupation/known habits; and association with colleagues/friends/family. As far as possible, the ideal would be to build much of this technology into a single device.
Each of these techniques is, at worst, a very real area of research in some stage of development – none are science fiction. Individually, they might be unavailable, inappropriate, unsuccessful or insufficient to produce a ‘perfect match’. However, together, they would combine to form a ‘personal fingerprint’ of the individual in different settings, in much the same way that identification services, such as Shazam, produce acoustic fingerprints for music under different conditions.
The necessary improvements in semantics and data-mining (b) are on-going. They essentially involve the usual Holy Grail of intelligent searching, answering the question that wasn’t asked. “He’s on an early-morning train to London, on the day of a test match, wearing a red and yellow tie: scan ‘MCC’ comments on Facebook posts/check-ins?”
But it’s important to realise that an automatic system for PoaT, doesn’t have to wait for a future when we have (a) and (b) in place. What we have now is good enough to start with. An ‘Auto-PoaT’ or ‘Shazam for People‘ service or application will simply improve its accuracy as the hardware and software technologies in (a) and (b) develop.
Now, (c) is the interesting one because it’s both:
- The point at which (a) and (b) are integrated into a complete, usable system, and
- The only part of the process where legislation may be effective if we want to stop this happening.
Because the process that’s required here is:
- The hardware at your disposal captures what distinguishing information it can and combines it with intelligent (probably local) software to produce a personal fingerprint,
- This personal fingerprint is matched against an online database to identify the individual, then
- As much information as is available can be returned to the ‘user’ of the ‘system’.
C is trivial. A is developing. The component that’s missing, at the moment, is the database in B – or possibly, its primary key, because the Internet may already be the database. A Shazam for People (SfP) app doesn’t yet have the simple, indexed online look-up for individuals that conventional Shazam has for music. Indeed, this is where legislation may have some chance of preventing it. But is such a perfectly coherent organisational structure really necessary? And could it be effectively prevented?
Collecting information in piecemeal form and making it available (mostly) isn’t illegal: the Internet has been doing it for years; and searching for it obviously isn’t (on the whole). So can the reduction of an individual person to a single, global identifier – with its associated data repository, necessary for SfP, be either achieved … or stopped?

Well, an email address, just as one example, is already a unique global identifier – used by many existing systems as ID. (No, not everyone currently has anything like an email address but project this whole discussion into the future.) Also, for some of us, information networks are springing up everywhere: in some cases, by our own hand (LinkedIn, Facebook, etc.); in others, independently (Google Scholar, for example). It’s not difficult to imagine these, and newer – more general, systems both expanding to cover larger numbers of people over the next few years and widening their spheres of interest as ‘Internet of Things’ technology makes more information available. It’s debatable whether these individual sources will ever get merged into a single ‘information super-page’ for everyone but the SfP software probably doesn’t need this – or an index to it: it will know where to look anyway. Unfortunately, this harvesting and storing of information centrally, or centralised indexing to multiple sources, may have been the only points at which data-protection legislation could have made any of this process illegal. Enforceably illegal, that is. But, without some form of protection, what might the future hold? Internet-based ‘big-data’ type analysis is already dredging up material many had hoped was buried in the past. What could happen in real–time when we combine accurate individual recognition, huge personal data-banks, fully integrated searches, opportunistic capitalism and anytime/anywhere delivery of results?

One thing’s for sure … Now may not be a good time to be hiding new skeletons in the cupboard; the old ones may be hard enough to keep in there!




August 25th, 2015 at 4:21 am
[…] The ‘Prof on a Train’ Game. […]
September 2nd, 2015 at 10:32 am
[…] follows on from last month’s post, in which we discussed the possibility of a future Shazam for People service and extends it to the […]
January 6th, 2016 at 1:10 pm
[…] and Privacy: Big Data + the Internet of Things = ‘Big Connectivity’. It will be very hard in future to keep anything secret. What effect will that have on us socially? No personal space? Also, we’ll probably […]
September 15th, 2016 at 11:17 am
[…] this is an area, which we’ve discussed before – many times so we won’t repeat old material. But, essentially, our data is very […]
October 1st, 2018 at 12:13 pm
[…] that was extended, through other articles; The ‘Prof on a Train’ Game and A Real Marauder’s Map, to describe a future in which none of us would have any privacy at […]
November 16th, 2018 at 1:16 pm
[…] paper’ to encourage submissions. What follows is an early draft of that (extended from The Prof on a Train Game) so it won’t hurt to get it ‘out there’ as soon as possible. Comments welcome […]
May 15th, 2019 at 9:46 am
[…] The ‘Prof on a Train’ Game […]
December 2nd, 2019 at 1:59 pm
[…] 2014: “A ‘Shazam for People’ recognition system will become available, able to identify anyone in the street and provide massive amounts of personal background information about them in real time” https://vicgrout.net/2014/08/20/shazam-for-people/ https://www.austinpublishinggroup.com/robotics-automation/fulltext/download.php?file=ajra-v1-id1001.pdf https://vicgrout.net/2015/08/23/the-prof-on-a-train-game/ […]