
That looks like a hopelessly vague question, and it is unless we’re prepared to clarify it a bit. On the other hand, we already know there are some impossible problems so surely there are some that are just hard? Again, we’ll need to work out what on earth we’re talking about here. Let’s start with what we actually mean by a problem in a computational sense …
(Be warned: There are one or two simplifications and liberties with precision in what follows; it’s well-intentioned but may upset the purist.)
Well, actually, even that isn’t simple and there’s no absolute agreement on what a good definition would be. (We’ve seen previously that mathematicians and computer scientists don’t always see eye-to-eye.) It’s cheating a bit but it’s probably easier to give examples and this should work well enough for us. At least in the context of computing, these are all valid problems:
- Calculate 2 x 4 + 9 – 3
- If 5 – x = 2 what’s x?
- Find the largest from 5, 7, 1, 4, 8, 5, 2, 4, 8, 5, 2, 6, 7, 7, 3, 3, 2, 4, 3, 6, 7, 7, 6, 5, 4
- Sort 25, 44, 66, 72, 12, 45, 56, 90, 45, 69, 11, 10, 12, 42, 88 into ascending order
- Arrange 1, 2, 3, 4, 5, 6, 7, 8, 9 into a magic square
- What’s the best way to get to Paris?
By comparison, these are examples of invalid problems:
- What’s the meaning of life, the universe and everything?
- What will this week’s lottery numbers be?
This merits a little discussion before we go any further. Problems 1-6 seem, in some sense, to be getting harder and, in fact, problem 6 might cause some distress to some. Is this a valid problem? What does it mean and how would we know the answer?
Well, in fact, that’s exactly the point. Provided we can agree on what we mean by ‘best’ (shortest, quickest, cheapest, safest, etc.) and so long as we have the necessary data to work with (a list of bus, train, boat, plane fares, fuel prices, distances, trouble-spots, etc.) then it is indeed a well-defined problem and we might be able to solve it. (Actually, that could still be beyond us; more to the point, we should be able to write a program for a computer to solve it.) What we can’t do is solve problems we don’t understand or work without data as in the two invalid examples.
Before we move on, it’s worth noting something else. How would you solve problem 2? Try out every possible value for x until we find one that works? No, of course not; that would take a ridiculously long time, arguably an infinitely long time (which would be awkward, even for a computer). We’d just do a little bit of algebra – some rearranging – and it’s only a few steps. Well, OK, that’s pretty obvious but we’ve already seen a more convincing example of good and bad problem-solving. There’s an early point to note here: we can’t just decide how hard a problem is on the basis of any old method (algorithm) we might use on it. The algorithm may be making the problem look harder than it is. But this throws up a very thorny question: how do we know we’ve got the best algorithm for a problem? Well, in general terms, we often don’t.
Let’s take a more interesting, actually a quite famous, example … The Travelling Salesman Problem (TSP) (yes, nowadays it should probably be the Travelling Salesperson Problem or something more politically correct but it just isn’t) models an itinerant pedlar moving from place to place, trying to sell their wares. In general terms they have to visit a number (usually ‘n‘) cities in some order, typically returning to where they started from. Assuming we can agree what we mean by ‘best’ in any given context (distance, cost, time, etc.), what’s the best order in which to visit the cities? Easy enough? Well, just consider how big the problem might be before we go any further.
OK, let’s start by considering how many possible solutions there are. We’re looking for the best ordering on n cities. How many choices for the first city? That’s n. How many for the second (having already chosen the first). That’s n-1. n-2 for the third and so on … When there are only two left, there are 2 choices for the second-to-last then only 1 for the last. So the total number of different solutions is n x n-1 x n-2 x … x 2 x 1, which we call n factorial and write as n! for short.
Factorials get very big, very quickly. (Suppose 1! = 1 is 1 metre away. 2! = 2 is two metres away. 6! = 720 is 720 metres away, maybe at the end of the street? Where are you at 12! ?) But computers are good at dealing with large numbers so is this really a problem? Well, in absolute terms (i.e. for a given value of n), it rather depends, but what definitely is difficult is the way these numbers grow as n grows.
Imagine we have a machine that can just about deal with a TSP of (oh, say) 20 cities. What that means (for now) is that it can examine the 20 x 19 x 18 x … x 2 x 1 = 20! possible solutions (forget the actual value of 20!; it doesn’t really matter) in a reasonable amount of time. A ‘reasonable amount’ of time, in turn, depends on the circumstances. (If you’re planning a Mars mission in five years’ time, you might have five years on a powerful computer; if you’re processing packets on an Internet router, you might only have a fraction of a second on a low-end processor.) Again, it doesn’t really matter; it’s a reference point, no more. A more relevant issue is what’s then involved in solving a TSP with one extra city?
Well, that’s 21! of course, which is 21 x 20!; in other words, 21 times as many possible solutions to search through. If we’re on the cutting edge of existing technology for 20 cities, then, even if Moore’s Law keeps going, it’s going to take a few years before we have a processor that’s up to it. That’s years just for that one extra city. Increasing to 30 cities, we’ll have to wait several decades for a suitable machine. What we’ve got now won’t save us; nor will our current rate of advance.
In fact, we can get quite fanciful about this … Let’s build the perfect computer … Suppose we turn the Universe into a computer and run it as efficiently as theoretically possible. Suppose every sub-atomic particle in the Universe is a component of the computer. Suppose we manage to perform a calculation every time a sub-atomic particle anywhere in the universe changes quantum state, for as many such particles as there are, for as many states as they can have, as often as such changes are possible and we run the whole thing for the lifetime of the Universe. (OK, we might be a bit hazy on the actual implementation details for this perfect computer but it’s just an exercise.) What’s the biggest TSP we can solve?
Amazingly, particularly in the context of problems like the TSP, that’s not such an impossible question to answer. Opinions will differ on some of the parameters (number of particles, lifetime of the universe, etc.) but the complexity of the TSP increases so quickly (it increases exponentially quickly) that a few orders of magnitude (powers of ten) here or there really don’t make that much difference. However you estimate these values, it turns out that the entire universe, acting as a perfect computer, probably can’t solve a TSP (by looking at all the possible solutions) for 100 cities. That’s an astonishing result; it means that a TSP of, say, 120 cities, whilst theoretically calculable, is as effectively unsolvable as the Halting Problem.
(A quick aside could be a good idea here. It might sound like we’re getting close to talking about quantum computing. We’re not really, although that might eventually have some relevance to these really big problems. We’ll have to leave that for a separate post.)
OK, there’s a huge assumption here of course. We’re working on the basis that the best or only way (algorithm) to solve a TSP is to try out all the possible routes, one at a time, to see which is best, and that might be as silly as it was for problem 2 at the start of this piece. If there’s a better way, it might not take anything like as long. Well, here’s the thing … no-one knows of an algorithm that’s very much better than the exhaustive search method we’ve been describing. (There are alternatives that bring the run time complexity down a bit, but not much, and generally at the expense of eating up huge amounts of memory space as they run. There are also a variety of approaches that exploit particular features of particular cases, but we’re talking in general terms here.) So does that mean that there’s no alternative method that’s (significantly) better? No, it just means we haven’t found one. By the same token, no-one’s ever proved that no such improved algorithm exists. So, where does that leave us?
Well, in simple terms, it means we don’t currently know how to solve big, general instances of some types of problem. More generally, we don’t know if we ever will. We need one of two things to resolve this: either an improved algorithm that ‘cracks’ the problem or a mathematical proof that no such algorithm can exist. Either’s conceivable and things have fallen out both ways in the past (although most mathematicians and computer scientists suspect the latter). But, at the heart of this little puzzle is a much deeper mystery because the TSP isn’t alone; there are a lot of other problems very, very like it.
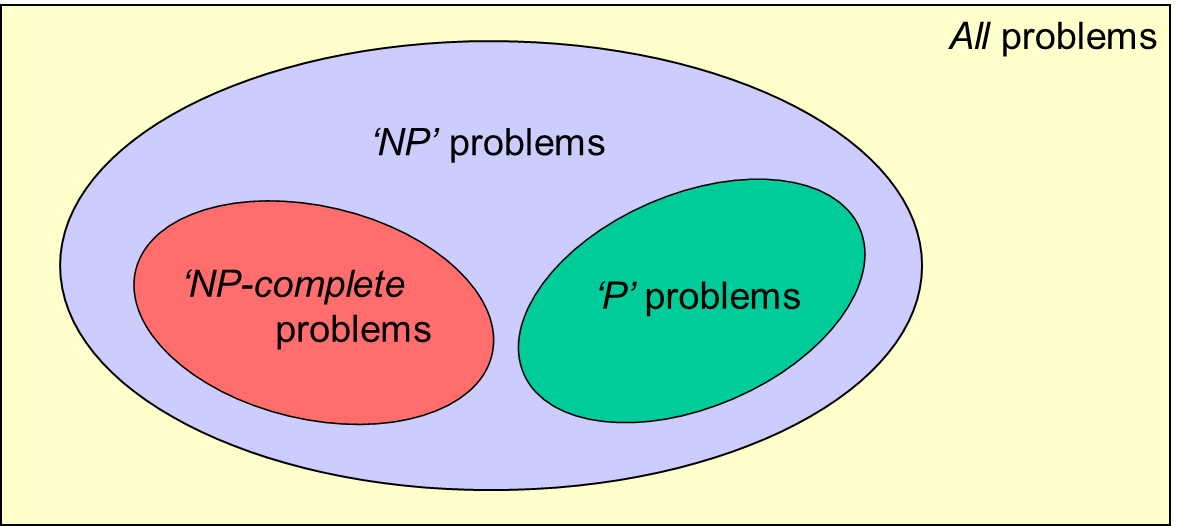
This (above) is what the situation might look like. Within the set of all problems, including the entirely unsolvable ones, lies a set of, for want of a better word, reasonable ones. These problems, grouped together under the heading ‘NP’ for historical reasons (we’ve kind of changed the definition since they were originally named although the result’s still the same) are any problems that, although it might be difficult to find a good solution, it’s easy enough to check a potential solution if someone hands it to us. Within NP, we know there are some easy problems, 1-6 above for example (which we call ‘P’). Then it seems, there’s another, non-intersecting set, which contains the TSP and its cousins, which we call ‘NP-complete’. (If you’re interested in what these letters actually mean, see here – as well as a more sophisticated version of that diagram and a few other ideas.) The problems in NP-complete are equivalent in the sense that:
- If we could find a simple algorithm for any one of them, it could be easily adapted to work for all of the rest
- If we could prove that no easy algorithm exists for any one of them, then this proof could be tweaked to prove the same for all of them
In other words, resolving the easy/hard question for any of the NP-complete problems would resolve it for all of them. If the problems in NP-complete really are hard (that is, if it’s not just collectively poor algorithmic design on behalf of the human race) then NP-complete is a distinct set from P. Or, even simpler, there are some NP problems that are not in P. P ≠ NP. If, on the other hand (and this would be a big surprise), someone finds an easy solution to an NP-complete problem, then all the NP-complete problems slide into P and P expands to become NP. P = NP.
So the situation, at the moment is that we may know if a problem’s easy; otherwise we’re not sure. To list a few simple, but unsettlingly diverse, examples:
- The ‘Shortest Path Problem‘, problem 6 above (finding the shortest route from one point to another) is EASY
- The ‘Shortest Tour Problem’, the TSP (finding the shortest way of visiting a number of points and returning to the start) appears to be HARD
- The ‘Minimum Spanning Tree Problem‘ (finding the least wire required to connect a wired network) is EASY
- The ‘Minimum Connected Dominating Set Problem‘ (finding the fewest relay switches to connect a wireless network) appears to be HARD
So, all in all, it’s pretty difficult to spot a pattern and the essential question remains unanswered. Is P = NP?. Apart from anything else, there’s a lot of money riding on it and it’s attracting the attention of the great minds of our time …

That’s a real snap from the Simpsons by the way; Homer’s brief dalliance with the world of mathematics. What’s interesting is that most of the equations and suchlike that float around Homer in this episode are known to be true. (The thing on the right, for example, is one of the most remarkable equations in mathematics. If you add 1 to both sides, it ties together the five key values known to mathematicians.) P = NP stands out as being something we don’t think is true. As MIT’s Scott Aaronson puts it,
“If P = NP, then the world would be a profoundly different place than we usually assume it to be. There would be no special value in ‘creative leaps,’ no fundamental gap between solving a problem and recognizing the solution once it’s found. Everyone who could appreciate a symphony would be Mozart; everyone who could follow a step-by-step argument would be Gauss…”
Despite all the expert opinion to the contrary, does Homer know something we don’t?




June 9th, 2013 at 9:22 pm
Regarding TSP-like problems, are there algorithms which can approximate an answer or give a reasonable good answer even if it cannot be proven to be the only or final answer?
On another blog, I somehow got to speculating about whether there could be a measure for interestingness and, if so, how could it be calculated. The topic came up on connection with chess. Part of what is interesting about chess is the number of permutations possible. For example, I think we could say it is definitely more interesting than tick-tack-toe which has a very limited range of plays. On the other hand, if the chess board was four times bigger and there were a lot more pieces the game might get less interesting because strategy would become impossible. This is much the same as the progression from easy problems (tic-tack-toe) to really hard, non-solvable problems (giant chess board). Any thoughts on whether the difficulty a problem could be measured?
June 10th, 2013 at 10:40 am
Yes, there are good number of ‘heuristics’ (approximations) for the TSP, and related problems, particularly for special cases, where the measure of cost satisfies some (often real-world) restriction. Possibly the best known is the ‘Christofides Algorithm’, which guarantees solutions within 50% of optimal for ‘road-map-type’ problems and similar. Other methods are known, through extensive testing, to perform excellently in practice, although they don’t often have theoretical guarantees.
I’d be interested to hear what others think about your ‘interesting’ measure for games and suchlike. Certainly, you make a valid point about the game-space potentially being too small OR too big to be interesting but there might be some objections to a single measure of ‘interesting’ in the way you suggest; two come to mind. Firstly, from an optimisation perspective, there’s no direct relationship between the size of a problem’s solution space and the complexity of the problem; some problems have infinite solution spaces but are easy to solve; playing a game is effectively executing a (probably heuristic) algorithm and much of the interest in probably in the algorithm – not explicitly the game. Secondly, a lot depends on people, of course; the ability to deal with the game-space is a crude measure of how good someone is at the game; some might struggle with simple games while others may excel at complex ones; a single measure is probably unrealistic?
An example of a game (for me) that’s just TOO complicated to be fun to play is ‘Reversi/Othello’, in which the entire balance of power of the game can completely flip over right at the end. Keeping the end in mind through all the permutations that lead up to it just seems impossible to me. But perhaps I haven’t played it enough and/or I’m just not very good at it?
July 1st, 2013 at 1:28 am
Sir,
Every problem in computation is potentially hard,but experience and step by step progress makes it easier. any branch of Computer science goes hand to hand with very strong hold on Mathematics especially Algebra and logarithms . Students should be encouraged to understand core foundation of computing from circuits to binary,programming to interfaces. There is an extremely thin layer between science and philosophy.
Thanks to read Sir.
November 28th, 2013 at 11:11 pm
[…] True enough, they use very efficient algorithms to achieve this factorisation, and factorisation is thought to be a difficult problem, but these numbers themselves are hardly breathtaking. Can quantum computers be built on any […]
January 12th, 2014 at 7:42 pm
[…] problem in algorithmic terms, whatever problem it’s now become appears to be very hard. We can’t be sure but it’s unlikely there will be efficient (i.e. quick) algorithms to solve it. Any attempt […]
February 3rd, 2014 at 9:12 pm
[…] cost solution will be the best. Examples are the Minimum Spanning Tree (MST) problem and the Travelling Salesman Problem (TSP). But there’s a crucial difference between these two: the MST has a simple algorithm […]
March 9th, 2015 at 12:49 pm
[…] itself for intelligence – has interesting parallels in Gödel’s Incompleteness Theorem, Turing’s earlier work with the Halting Problem and is essentially similar to the question of whether wizards think they’re doing […]